

Creating Custom SQL CLR User-Defined Types
Posted by Keith Elder | Posted in .Net, SQL Server | Posted on 29-10-2007
Since SQL Server 2005 .Net developers and DBAs have had the ability to create custom SQL CLR types. It wasn’t until recent I found a few uses for them. Not only did I find a use for them but a DBA who is a team member did as well. If you would like more information about SQL CLR types or are new to them start by reading the introduction here. What follows is a walk through from start to finish creating a user-defined type (UDT). The project source code is available at the end of the article.
Maintaining Data Integrity
One of the advantages of SQL CLR User-Defined Types is the ability to store complex information in SQL Server and guarantee the integrity of the data. For example, let’s say a database is fed information from an SSIS package at night that has to move email address information from one system to another. How would one guarantee the email address field is valid as it is moved from system A to system B? Obviously that would have to be build that into the SSIS package somehow. But does that “really” guarantee another SSIS package a Jr. Database Engineer wrote does the same validation? No it doesn’t. Removing SSIS packages from the equation we still have to worry about end-user input and hope our developers from various teams or platforms follow the same validation rules. It is a tough balancing act to say the least. Having data integrity close to the data store has its advantages since everything coming into the database must pass the data integrity spec. This is where a SQL CLR User-Defined Type can come into play. Instead of creating a column to store email address in a type of varchar(50) or whatever your company uses as a design standard, we could create a SQL CLR User-Defined Type of “EmailAddress”. Within the .Net runtime we could easily validate the integrity of the email address and throw an exception if it doesn’t match. We could also split apart the domain and prefix values if we wanted to pull out all email addresses for the domain keithelder.net. Let’s look at an example.
Creating Your Project
To get started creating a SQL CLR type we first need to create a project that understands how to build SQL Server types. To do this open up Visual Studio and point to Database Projects (assuming you installed the database components) and select SQL-CLR. Then chose the language for your project. In our case we are going to select C#.

After the project is created the first thing to do is to create a folder to store the various types. It isn’t wise to just start adding different CLR types to the project, things will get messy. Right click the project and add a folder called “Types”.
After you’ve added the folder, right click the folder and click “New Item”. Select User-Defined Type from the menu and give your type the name of the type you want displayed in SQL Server (important).
In this example I am calling the type “EmailAddress”. Once entered click add.
Project Cleanup
After the custom user-defined type is added to Visual Studio the code should look like this.
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedType(Format.Native)]
public struct EmailAddress : INullable
{
public override string ToString()
{
// Replace the following code with your code
return "";
}
public bool IsNull
{
get
{
// Put your code here
return m_Null;
}
}
public static EmailAddress Null
{
get
{
EmailAddress h = new EmailAddress();
h.m_Null = true;
return h;
}
}
public static EmailAddress Parse(SqlString s)
{
if (s.IsNull)
return Null;
EmailAddress u = new EmailAddress();
// Put your code here
return u;
}
// This is a place-holder method
public string Method1()
{
//Insert method code here
return "Hello";
}
// This is a place-holder static method
public static SqlString Method2()
{
//Insert method code here
return new SqlString("Hello");
}
// This is a place-holder field member
public int var1;
// Private member
private bool m_Null;
}
There are several things we do not need here as well as some refactoring we need to do. Let’s clean things up a bit.
First thing I suggest is to remove the Method*() methods. They aren’t needed, they are just place holders. The next thing is to refactor the m_Null variable. Personal choice here but I can’t stand the naming convention of m_. It irks me to no end. It must die.
The next thing we need to do is create a variable to hold our email address value. Since our type is called EmailAddress I am going to call this new property Value. After the cleanup is done we should have something similar to this.
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedType(Format.Native)]
public struct EmailAddress : INullable
{
private string _value;
/// <summary>
/// The email address value.
/// </summary>
public string Value
{
get { return _value; }
set { _value = value; }
}
public override string ToString()
{
return _value;
}
private bool _isNull;
public bool IsNull
{
get
{
return _isNull;
}
}
public static EmailAddress Null
{
get
{
EmailAddress h = new EmailAddress();
h._isNull = true;
return h;
}
}
public static EmailAddress Parse(SqlString s)
{
if (s.IsNull)
return Null;
EmailAddress u = new EmailAddress();
// Put your code here
return u;
}
}
Coding Our Logic
We are now ready to put in our own logic to validate our email address along with some other features.
To start with let’s add a method to the code to validate the email address. In this example I am going to use a regular expression that simply validates the integrity of the data. Notice I didn’t use the word “validates” because validation of an email and and data integrity are two different things. Integrity just checks to make sure my data is in the proper format. It handles finding problem email addresses liked @asdf.com or blah@ and so on. Whether the email address is actually valid and it works is a totally different story that requires the use of business services. This is not the point here. We just want to make sure that if someone is going to store an email address in our database it adheres to some type of data integrity and that our database will not except any text a developer throws at it. Think of it as “gate keeper logic”.
After we add our validation logic we are going to add a call in the Parse(SqlString s) method. This is where we are going to call our validation. The new code will look something like this:
public static EmailAddress Parse(SqlString s)
{
if (s.IsNull)
return Null;
EmailAddress email = new EmailAddress();
if (email.ValidateEmail(s))
{
email.Value = s.ToString();
return email;
}
else
{
throw new SqlTypeException("The email " + s.ToString() + " was not in the proper format.");
}
}
/// <summary>
/// Validates the email being passed in.
/// </summary>
/// <param name="email"></param>
/// <returns></returns>
public bool ValidateEmail(SqlString email)
{
bool isValid = false;
if (this.IsNull)
{
return true;
}
isValid = Regex.IsMatch(email.ToString(), @"^[\w-]+(?:\.[\w-]+)*@(?:[\w-]+\.)+[a-zA-Z]{2,7}$");
if (isValid)
{
return true;
}
else
{
return false;
}
}
Fixing Serialization
At this point if build our solution it will work. However, if we right click our project and click “Deploy” it will fail with the following error.

The reason is we have the email address as a string and we also have the object attributed with the serialization of Format.Native.
[Microsoft.SqlServer.Server.SqlUserDefinedType(Format.Native)]
The native format can only store value types, not referenced types. This means it is limited as to what we can use (bool, int, etc). String is not one of these so we need to create our own user-defined format. Don’t worry, it isn’t as hard as it sounds. The first step is to change the attribute to this:
[Microsoft.SqlServer.Server.SqlUserDefinedType(Format.UserDefined,IsByteOrdered=true,MaxByteSize=8000)]
Set the format to UserDefined, the IsByteOrder to true and the MaxByteSize to 8000. Setting the format to UserDefined allows us to then put our own logic in place. We do this by implementing IBinarySerialize in our custom type as we’ll see later on. The IsByteOrdered option set to true guarantees the serialized binary data can be used for semantic ordering of the information. This allows us to use the same operations in SQL Server as in managed code. See this page for all of the options this enables like creating indexes, group by and more. MaxByteSize can only be as large as 8000 bytes so we essentially set it the largest value. If you know the value is going to require less information, set it to that value. Yes in this case 8000 is more than an overkill for email addresses but I put it there so I could explain that 8000 is the largest the value can be. Important to know.
Once we have our attribute setup properly we need to implement the interface IBinarySerialize as I mentioned. There are only two methods to this interface: read and write. Since we only have one property we are going to be storing this is pretty simple. Here are the two methods implemented.
public void Write(BinaryWriter w)
{
w.Write(_value);
}
public void Read(BinaryReader r)
{
_value = r.ReadString();
}
Ready To Deploy
As you see creating our own user-defined format wasn’t that bad. Only a few lines of code. At this point the project should build and should be deployable to the database. To deploy the EmailAddress type to the database right click the project in Visual Studio and chose “Deploy”. After it is deployed it should appear in the User-defined types under the Programmability section within SQL Server Studio as follows.
Using Our UDT in A Column
Once the UDT is deployed into the database we can associate our new type as the “Data Type” with a column in the database. If we create a new table we’ll see the new type in the drop down.
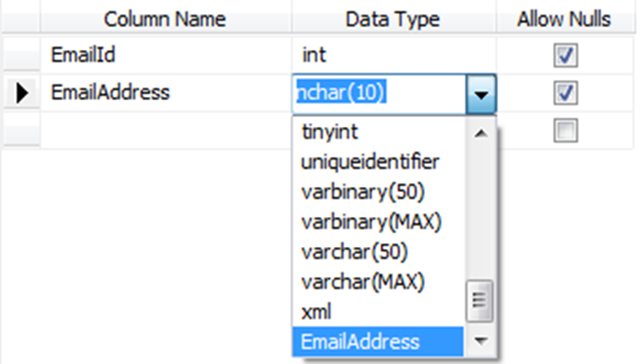
Cool! Yes and now we start thinking about other UDT’s such as phone numbers, zip codes, and more. Where do we stop!?
Using Our New EmailAddress User-Defined Type
Now that we have a table to put our emails in. Let’s add some email addresses to it and start playing around. I added four email addresses to mine to initially play with. After the “fake data” is entered, do a “select * from Email” T-SQL query to see the results of the data. It should look like this:
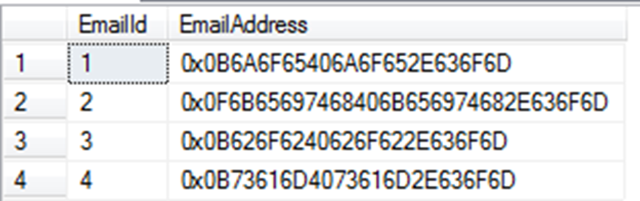
Whoa! Yes, this is scary. The reason has to do with the format the database is storing our data. Since we were not able to use the native format we can’t see the data as expected. If you reference the code after we cleaned up you’ll remember there was a “Value” property in our object. The good news is we can use this property to get at and see our data. Let’s rewrite our query using that property like this:
select EmailId, EmailAddress.Value as Email from Email
The result of running this will be:
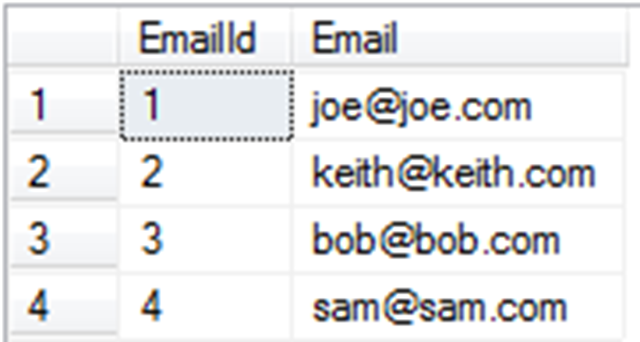
This is why I chose the naming convention of “Value” for this field since it seems a little weird to type EmailAddress.EmailAddress or EmailAddress.Email. It made sense to just ask for the value stored. I hope that makes sense.
Checking Our Validation
Now that we are able to select data properly from our table let’s look at how our validation works. Here is the SQL query we are going to issue to SQL Server.
INSERT INTO [CARI2].[dbo].[Email]
([EmailAddress])
VALUES
('fakeaddress')
Of course the email address of “fakeaddress” shouldn’t pass our data integrity. If we run this command on our table the following error is generated.
Msg 6522, Level 16, State 2, Line 1
A .NET Framework error occurred during execution of user-defined routine or aggregate "EmailAddress":
System.Data.SqlTypes.SqlTypeException: The email fakeaddress was not in the proper format.
System.Data.SqlTypes.SqlTypeException:
at EmailAddress.Parse(SqlString s)
.
The statement has been terminated.
This is exactly what we wanted since this stops anyone from entering data into our database that doesn’t pass our integrity check. This means that neither an SSIS package running in the middle of the night nor an end-user is able to insert erroneous information into our data store. Business problem solved.
Advance Queries and Extension Properties
It is important to remember that our custom type is merely an object. As with any object we can add methods or properties to that object. Here are some examples to get your brain turning.
Let’s start with the example looking up all users that are in the domain “keith.com”. How would we do that? The trick is to remember we have to reference the .Value of the column to get to the data (this was the public property we created). If you keep this in mind then it is like any other query. Here’s an example:
select EmailId, EmailAddress.Value as Email from Email where EmailAddress.Value like '%keith.com'
A side note, SQL Server Studio does not give you intellisense when typing so it is important whatever names you come up with you standardize on to not confuse your team members.
What if we wanted to do a distinct lookup of domains or to print the domain or the prefix values of the emails for data mining purposes? In these cases you can chose to add extension properties to your object. Below is the code for two examples using the prefix and the domain.
/// <summary>
/// The part of the email address before the @ sign.
/// </summary>
public string Prefix
{
get
{
string[] x = Value.Split('@');
return x[0];
}
}
/// <summary>
/// The domain of the email address.
/// </summary>
public string Domain
{
get
{
string[] x = Value.Split('@');
return x[1];
}
}
As you see we are using the Split method to split our email address string into two parts using @ sign. Instead of doing the like clause the way did it above that can now be expressed like the following:
select EmailId, EmailAddress.Value as Email from Email where EmailAddress.Domain='keith.com'
We can also do this now:
select EmailId, EmailAddress.Domain as Domain from Email
Which would yield us this:
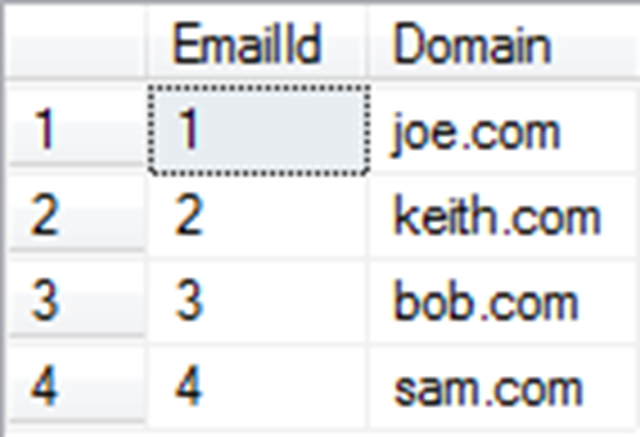
Or we can do a distinct lookup like this which provides us with a much cleaner T-SQL syntax.
select distinct(EmailAddress.Domain) as Domain from Email
While this is all neat and good let me point out that I haven’t done any extensive performance tests to see which method performs better so be sure you do that before using one over the other.
Updating Your User-Defined Type
So far it has all been shiny pennies up until this point. Watch out though here comes a rusty washer.
When you update your UDT you are going to have to drop the UDT from any columns that use it, and then redeploy and then re-add. Obviously this can be scripted but it is a pain, especially if you are dealing with tables that have millions of rows so be careful. If your only goal is to get data integrity you may be better off using a user-defined trigger instead. The bottom line is to make sure your UDT doesn’t change or need to change once you deploy it.
Conclusion
That’s it folks, a start to finish nuts and bolts of building user defined-types in SQL CLR. Wasn’t it exciting? I hope this helps those that are investigating SQL CLR User-Defined Types.
Thank you very much for this article…
@Ryan,
The was quite possibly thee worst “advice” I’ve ever read. Seriously … wow.
@Ryan – hilarious – if people were all as dumb as you then we wouldn’t need any data types other than varchars… everything could just be stored as text
If the table was designed to hold the two parts of the address in two different columns, you wouldn’t need this function in the first place. That would be the more correct approach.
In most cases, custom types are made because people don’t understand the problem fully.
you are the great, your post is helpful to me.
One tip for redeploying UDT’s without having to drop the column and its data: just change it to a string of sufficient size (use NVARCHAR(MAX) if you can’t decide), since by contract all SQL Server types must support serialization to/from a string. So long as your new type is able to Parse() the string representation of the old type, all you’ll need to do after deployment is change the column type back.