How To Load an Embedded Resource From A DLL
Posted by Keith Elder | Posted in .Net | Posted on 14-12-2007
12
When developing class libraries in .Net there are times we utilize XML files to store static information or icons and bitmaps associated with components in our class libraries. During the build process we have several build actions to choose from that allow us to handle different scenarios. For icons used in components or static XML files it makes a lot of sense to package those files into the DLL so they can go along for the ride. We call this an embedded resource.
For those that are curious the .Net framework has a lot of embedded resources. For example have you ever wondered where an icon came from after you dragged and dropped a component onto the designer? Take the BindingNavigator that has icons for next, previous, delete, save, etc. Those are all embedded within the DLL. This is great because a developer just adds the one DLL to the project and it works. No other files need to be added to the solution in order to make the component it work.
If you have a common or standard library that reads a lot of static information from XML files or text files, consider packaging those files as an embedded resource within the DLL. This way when a user adds your DLL to their project they don’t have to even think about where it is getting its data. It is already in the DLL. Let’s look at an example of how this is done.
Embedding Our Data
I created a sample console application and I added an XML file into my solution which holds southern states. Here is the file:
<?xml version="1.0" encoding="utf-8" ?>
<SouthernStates>
<State>
<Name>Mississippi</Name>
<Abbreviation>MS</Abbreviation>
</State>
<State>
<Name>Tennesse</Name>
<Abbreviation>TN</Abbreviation>
</State>
<State>
<Name>Arkansas</Name>
<Abbreviation>AR</Abbreviation>
</State>
<State>
<Name>Louisiana</Name>
<Abbreviation>LA</Abbreviation>
</State>
<State>
<Name>Georiga</Name>
<Abbreviation>GA</Abbreviation>
</State>
<State>
<Name>Florida</Name>
<Abbreviation>FL</Abbreviation>
</State>
</States>
Obviously this information isn’t going to change anytime soon so I can sleep at night knowing this information really doesn’t have to be dynamic and be read from a database. Here is what my solution in Visual Studio looks like:
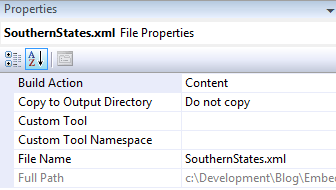
Right clicking on the SouthernStates.xml file within the project and selecting properties we see the file will be treated as standard content during the build process and will not be copied to the output directory (debug or release).
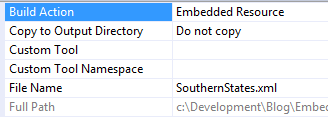
To make this an Embedded Resource all we have to do is change the “Build Action” to “Embedded Resource”.
Now if we do a build on our project and look at the debug folder we only see our host executable along with the EmbeddedResource.Library.dll, and no SouthernStates.xml file. To check if the XML file is in the DLL open a plain text editor and open the DLL the file was embedded in. The file embedded should be able to be viewed in plain text with the editor. Here’s a screen shot using Notepad++.

Accessing the Embedded Resource
Embedding the XML into the DLL is the easy part! The question is how to get this data out so it can be accessed. It isn’t that hard really. About two lines of code using Reflection to get the data is all that is needed. Since this example is using state related information I decided to build this example using a strong typed collection. In my example I created two classes: State and StatesCollection. These classes will provide a strongly typed way of accessing the information in the XML file.
The State object created has two properties: Name and Abbreviation. Basically the properties map to the data in the XML file. Here is the State class:
public class State
{
public string Name { get; set; }
public string Abbreviation { get; set; }
}
For the StatesCollection I chose to inherit from a generic list and use a lazy loading property called SouthernStates so the values from the XML file would only get read once. Taking this approach allows access to all of the features of a generic list (Find(), Sort(), Skip<>, Take<>, etc). Here is the initial stub of StatesCollection.
public class StatesCollection : System.Collections.Generic.List<State>
{
private StatesCollection()
{
}
private static StatesCollection _southernStates = null;
public static StatesCollection SouthernStates
{
get
{
if (_southernStates == null)
{
}
else
{
return _southernStates;
}
}
}
}
All that is left now is to fill in the code within the getter of our property to load the data from the embedded DLL. The first thing needed is to get access to the assembly the code is executing within. The second thing needed is to get the XML document into something we can work with. Here are the two lines to perform this:
System.Reflection.Assembly asm = Assembly.GetExecutingAssembly();
System.IO.Stream xmlStream = asm.GetManifestResourceStream("EmbeddedResource.Library.Data.SouthernStates.xml");
The main thing to note is the string passed into GetManifestResourceStream() is the full path including namespace to where the file lives within the project. Normally if an exception is thrown when you first try this, this is the cause of the problem. If the path to the file is not clear then open the DLL with a plain text editor and search for the filename. Use the path noted in the DLL. Here’s a screen shot of what this may look like in the DLL:

Now that the XML data is in a stream there are several ways to access this data. In this example I chose to load the stream into an XmlDocument and then process the nodes in the XmlDocument. The following code fills in the getter property of the SouthernStates property in the StatesCollection class.
if (_southernStates == null)
{
StatesCollection states = new StatesCollection();
try
{
System.Reflection.Assembly asm = Assembly.GetExecutingAssembly();
System.IO.Stream xmlStream = asm.GetManifestResourceStream("EmbeddedResource.Library.Data.SouthernStates.xml");
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.Load(xmlStream);
XmlNodeList nodes = xmlDoc.SelectNodes("/States/State");
StatesCollection coll = new StatesCollection();
foreach (XmlNode node in nodes)
{
State state = new State();
state.Abbreviation = node["Abbreviation"].InnerText;
state.Name = node["Name"].InnerText;
coll.Add(state);
}
return coll;
}
catch (Exception ex)
{
throw new Exception(ex.Message);
}
}
else
{
return _southernStates;
}
Embedded Resource In Action
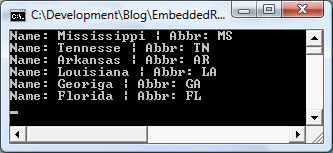
The hard part is now over. In the above example notice after GetManifestResourceStream() is called the result is a stream. Using the stream the XML data can be easily loaded into the XmlDocument using the Load() method. After the data is loaded into the XmlDocument all that is left is to loop through the XmlDocument and build up a collection of State objects. To test this example it becomes extremely trivial. Here is a sample that prints the information in the XML file to the console.
foreach (State state in StatesCollection.SouthernStates)
{
Console.WriteLine("Name: " + state.Name + " | Abbr: " + state.Abbreviation);
}
Console.ReadLine();
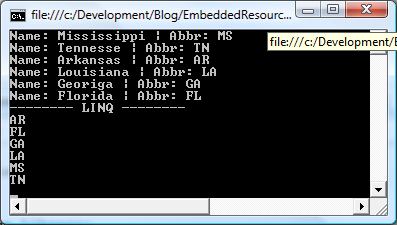
To take the example a step further LINQ could be used to sort the collection and return values easily. This is the added benefit of using a strongly typed collection as eluded to earlier. Here’s a sample using LINQ to sort the abbreviations and return them sorted.
var q = from state in StatesCollection.SouthernStates
orderby state.Name ascending
select state.Abbreviation;
List<string> sortedStates = q.ToList<string>();
for (int i = 0; i < sortedStates.Count; i++)
{
Console.WriteLine(sortedStates[i]);
}
While a little scary at first, embedded resource files aren’t that difficult to deal with and provide a lot of value if used correctly. Obviously if the data in the XML changes constantly this is going to require a new build of the DLL. A decision will have to be made on the part of the developer if this is acceptable. Feel free to download the sample solution below and play around.