Datasets vs Business Entities
Posted by Keith Elder | Posted in .Net, Smart Clients, Web Services | Posted on 26-10-2007
5
If you are an experienced .Net developer more than likely you’ve come to a cross roads of sorts in development over which object model to go with. Do you use Strong-Typed Datasets or should you write your own business entities from scratch or generate business entities using an ORM. A reader emailed me asking my opinion the other day and the very question was also raised on Twitter by Joel Ross yesterday as well. Here are my words of wisdom on the subject matter to help you hopefully arrive at a conclusion which road you may want to travel.
Things to Think About
What are you going to do with the data? This is the most important question to ask your self. The reason is Datasets and business entities solve two different problems and where one makes life easy in one example it overly complicates the heck out of another problem. Let’s take a simple scenario that any Smart Client developer may run into. For example, let’s say you are instructed to build a search screen within your application and bind the results to a DataGridView. The user interface should allow an end-user to search and return joined row data from the data store. After the data arrives to the client the end-user needs the ability to filter, group, and sort the data within the client. What do you do? Here is a rough draft of what we need.
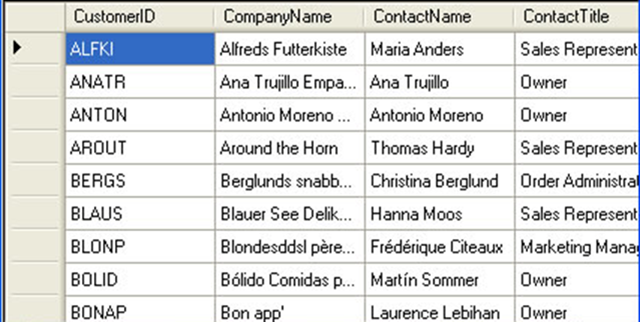
In this case my default answer is a plain Dataset. There are a few things to think about in this scenario. The first one is how often the screen data might change. In the example above it is returning CustomerId, CompanyName and ContactName and ContactTitle to the end-user. The question is how do we handle a simple change if the business requirement changes a month from now and we need to add a new column of Email to the result set? Let’s look at the three options we could go with to tackle this scenario. It helps to visualize it on paper.
| Non-Typed Dataset | Typed Dataset | Business Entity | |
| Fastest Development Time | X | ||
| Requires Custom Programming for filter and sort | X | ||
| Requires Re-deploying Client To Add New Column | X | X | |
| Requires Re-deploying Service To Add New Column | X | X | X |
| Heaviest Payload | X |
Looking at the table we see the non-typed Dataset has the fewest checks (one less). While it isn’t the fastest to develop because we do not get all of the automatic pre-built bindings it is still pretty fast. Much faster than the custom business entity. Even then we still don’t have to write our own sorting and filtering routines nor do we have to redeploy our client. Having to redeploy is the biggest cost to a business and should be taken very seriously when developing Smart Clients for the enterprise. Downtime is not cool in any business, even if it only takes a minute for a ClickOnce app to be redeployed. In this scenario all we’d have to do is change the way we fill our Dataset within our middle tier (services layer) and then send it down the wire. This change could be made pretty much whenever we want without having to interrupt the business. Notice we get the flexibility of being able to change our business requirements on the fly so to speak, but we are using the heaviest payload to send our data over the wire to our client. If you aren’t familiar with why the strong-typed Datasets can have smaller payloads via web services over the wire then read this tip on strong-typed Datasets and web services.
Is the Data Really an Entity?
The above example didn’t favor very well for using an entity. Why? I think it has to do with the fact that the problem we were trying to solve didn’t match itself well to an entity. I even question if the results from a search in this scenario is an entity. I argue that it isn’t, it is a result set based on an action. Not a true business entity. If we think of the entity above as a Customer entity we would have a lot more properties within the Customer entity. For example addresses, contact information, orders maybe and so on. In our scenario we didn’t need any of that data to be filled. As with most ORM mappers which help developers build entities, this is where a lot of them fall short in the fact that only a few properties need to be loaded, yet we have to pay the entity tax as I call it just to get to a few fields of data and load all the data within the entity.
What if we created a brand new entity with just the four fields we needed to display? While we could create a plain old collection of C# objects that only have the fields we need, we are still back to the problem of filtering, sorting, grouping and deployment.
In this scenario: Dataset 1 Entity 0
Another Scenario
To take our example a little further, what would we do if the end-user was able to double-click one of the rows that was returned from the search? The end-user would then be presented with a new screen so they could edit the customer record and see other data like address information, contact information and so on. What would we do in this case?
In this scenario we are truly dealing with an entity. We are dealing with a Customer entity and it makes perfect sense to handle all of our bindings directly to a business entity. Sure we have to bake in all of the OnChange events, validation, and so on, but the end result is we have a very flexible way of dealing with our Customer. Maintaining customer information in just a Dataset scenario is slow, lots of overhead and isn’t near as clean as just a plain old C# object (or entity, however you think of it). We can wrap our Customer entity with policy injection and validation much cleaner than we can trying to represent a Customer in a DataSet no matter how we look at it.
In this scenario: Dataset 1 Entity 1
Deadlines and Size of Application
When it comes to making a decision in your applications I say use common sense when it comes to what you are developing. Honestly if I’m building a one or two page web form for internal use within our company, I’m cutting corners to get the thing done. I want it to work and make the client happy but then move on. Datasets here I come! On larger applications though that isn’t the case. For example if you are building a commercial web site or large scale enterprise app the code base will be taken more seriously. There will be plenty of time to identify entities and put in the proper plumbing such as filtering, sorting, grouping, change tracking and more. You may also take the time to explore one of the many entity frameworks available for .Net as well to give yourself a jump start.
Conclusion
No matter how many times we argue the benefits and merits of one versus another I think the best approach a developer can take when it comes to Datasets vs the entity argument is take a holistic approach at the problem that he or she is trying to be solve. Don’t forget to take into account future changes and how much maintenance may be required. Use common sense and match the best solution to the problem. I hope this helps and is now officially clear as mud.